It’s probably being operated in the service of music rather than “sound effects.”
Please Remember:
The opinions expressed are mine only. These opinions do not necessarily reflect anybody else’s opinions. I do not own, operate, manage, or represent any band, venue, or company that I talk about, unless explicitly noted.

 Want to use this image for something else? Great! Click it for the link to a high-res or resolution-independent version.
Want to use this image for something else? Great! Click it for the link to a high-res or resolution-independent version.One of the perks of my job is that I get to regularly hear great bass players. My saying that might surprise some folks, because I’m NOT in the camp that believes that kick and bass are the most important elements of a song. My priorities list is not, however, my “want” list. Believe me, I WANT great bass. It most certainly is part of the whole experience, and if it’s not in the right spot, the experience isn’t all it could be.
So, when I get great bass, I’m a happy guy. If I’m getting great bass, it’s because the player knows what they’re doing. Obviously, being able to actually manipulate the stringed instrument is key, but there’s another element. That element is the rig, and the effective use thereof.
The “effective use” bit is REALLY important by the way.
I’ve seen lots of bass-amp setups over the years. Just sitting on the deck without making noise, some of them were more impressive than others. What’s amazing is how little that actually tells you. I’ve heard relatively diminutive rigs that were a joy to work with, and giant setups that made me check a clock every two minutes: “This is painfully bad. Is it time to go home yet?” (Yes, I’ve also had impressive looking setups that sounded fantastic. Case in point – the rig pictured above, which belongs to Ray Opheikins. Ray IS Geddy Lee, as far as I can tell.)
Whether the “I love the sound of this bass-player!” experience was coming from a big or small setup, I’m pretty sure I can distill the root cause down to one thing: The bass rig was being used to perfectly fit into a musical part, rather than to create “sound effects.” That is, the player’s main goal was to produce actual notes that all matter, instead of just rumble and boom. The mental maturity required for this is significant, but that’s beyond the scope of this article. What I really want to talk about are some of the technical aspects of making this happen.
We Built A Hill, But We Wanted Flat Ground
All sorts of folks fall into the rumble-n-boom crowd, but one particularly troubled subgroup is the “bass knob all the way up” tribe. This is a well-intentioned crew. They want to have fun, and they want the crowd to have fun, but they think that the fun is contained primarily in the feel of deep bass. So…they gun the lowest frequency controls on their tone stacks. What they think is happening is that they’re grabbing the deep end only, but that has a good chance of not being the case. What’s really likely to happen is that they grab the subwoofer material AND a big pile of peaky, muddy, boomy, garble that lives above that…and is proportionally much louder.
Now, I can’t substantiate all of this directly, but I can put forth a model that I think fits into my experience.
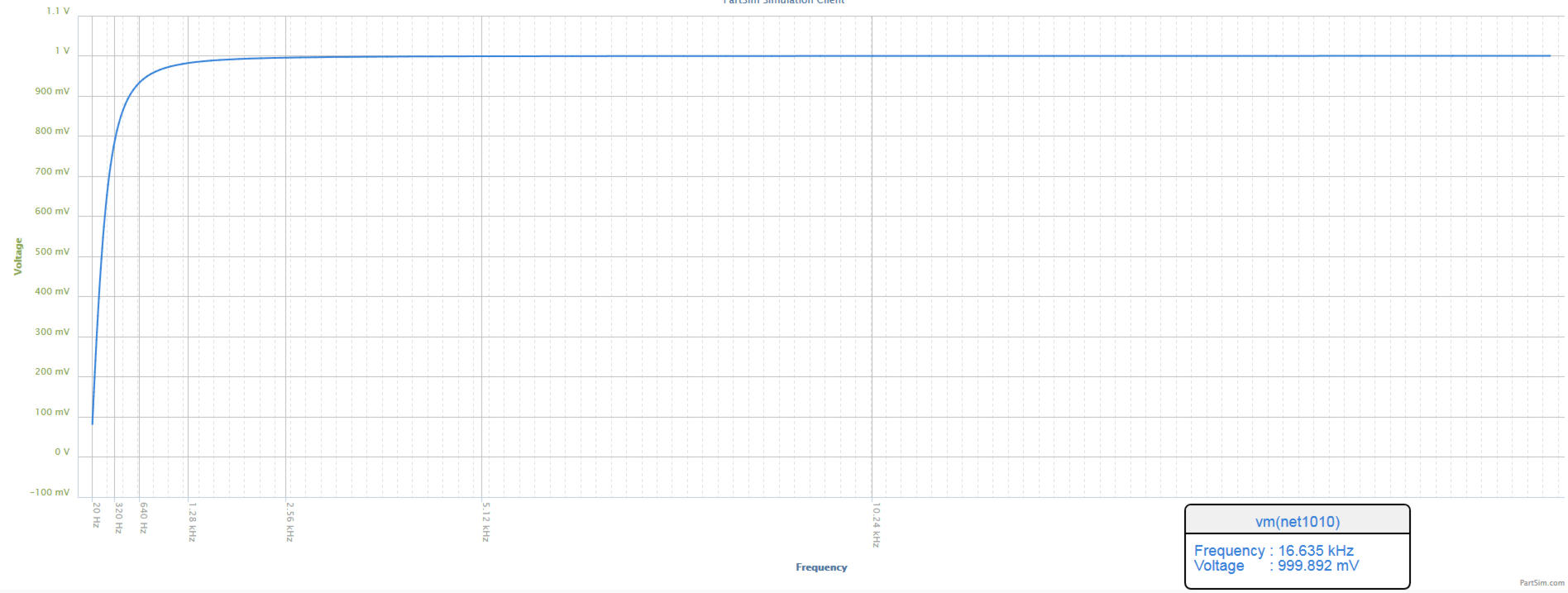
The misconception that I think is occurring is that the player is assuming the overall response of their rig to be flat down to 0 Hz. However, my guess is that many bass setups look more like this:
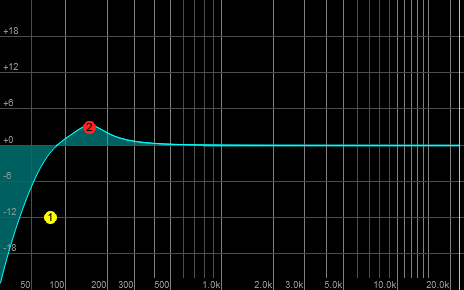
It’s possible to flatten that response all the way down to 40 Hz (a hair below the normal tuning of a bass guitar’s E string), but it requires a couple of precisely placed and highly flexible parametric filters.
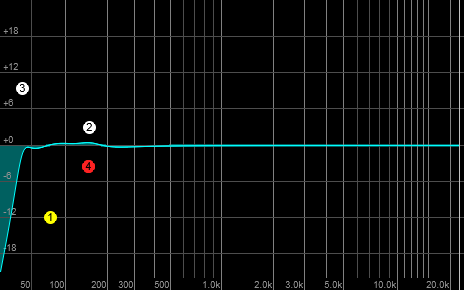
Precisely placed and highly flexible parametric filters aren’t usually what you find on a bass amp. If you’re talking about the low end, you probably have a shelving filter with a corner frequency of 100 Hz. Turn it all the way to the right and add it to the natural response of everything, and…
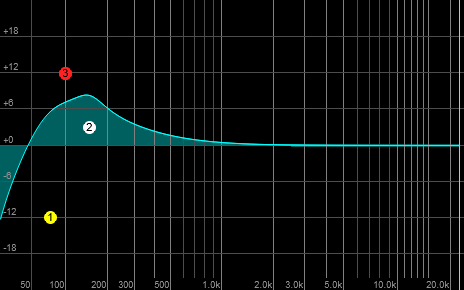
You get this huge “hill” between 75 Hz and 200 Hz, with a bit of a peak around 150 Hz. Depending on the instrument, the player, and the room, this can be a real recipe for mud, overwhelming resonance that’s nasty to listen to, and “one-note bass” (where a few tones really pop out, and everything else disappears). It’s entirely possible for the actual frequency response of a real rig in a real room to be far more extreme than what I’m depicting here. That means the addition from the low-frequency boost makes things even worse. Yes, the deeper tones did come up, but a lot of other material also rose in level…and in higher proportion. Plus, the higher frequencies, where the actual clarity of the bass comes through, are in danger of being drowned.
Irony: It’s Not Actually “All About Dat Bass”
The preceding fits into my next point, which is, surprisingly, that really effective bass isn’t necessarily “deep.” It can be, of course, which is seriously fun.
But really good bass, bass that can work beautifully in a song and sound as good as possible in lots of different venues, seems to rely far less on “deep” than “smooth.” Also, the “smooth” has to happen rather higher than might be intuitive.
First, there are lots of PA systems out there that I would personally consider to be “pro” that are very definitely NOT flat down to 40 Hz. At that point, they’re probably at least 6 – 10 dB down from the rest of their passband. In other words, the flat-tuned system might play at a certain sound pressure when driven with 1000 watts at, say, 1 kHz. If you wanted that same sound pressure at 40 Hz, you would need to be able to safely drive the system with 4000 to 10,000 (!) watts. A PA that can actually deliver 40 Hz or below at a comparable level to the midrange is a large, expensive creature with a voracious appetite for electricity.
Second, even dedicated bass cabs don’t go that low. The venerable and much coveted Ampeg 8X10 is advertised to be 3 dB down at 58 Hz, and 10 dB down at 40 Hz.
Now…
I’m not saying that a combination of playing style, EQ, and compression can’t compensate for that. You might be able to pull everything else down to match that 40 Hz level.
But do you see how that proves my point?
If you pull everything else down to match the really deep frequencies, you’ve created a very smooth response at the cost of total output. (This is not a bad tradeoff, unless you don’t have enough output, at which point the rest of the band needs to give you some space. Seriously, you don’t need new gear. They need to cooperate with YOU. Anyway…)
The smoothness is the key – and it’s especially key in the critical range of about 80 – 320 Hz. That’s a two-octave band which starts at the first harmonic of your low E string. As a sound operator, I’ve found that when the 80 – 320 Hz area is gotten right (both in and of itself and with any tweaks necessary to fit the band) the bass player’s contribution tends to be nicely audible at all times and in a wide variety of positions within the venue. That passband is reliably doable by a wide variety of bass amplifiers and PA systems. Keeping that range smooth, with gentle transitions to the rest of the audible frequency band, is also a great weapon against bad acoustics and poorly tuned PA systems. You’re far less likely to aggravate a nasty standing wave for the folks standing in the areas where the peaks form, and you’re also far less likely to aggravate a peak in the audio system’s response.
Also, if you start with a really smooth rig, you have the option of dialing in a peak or dip to fit the band’s sound. If the amp’s “starting point” response looks like the Himalayas, you’re stuck with that being stamped onto whatever else you’re trying to do.
Again, it’s not that deep bass isn’t cool. If that’s THE thing your sound stands or falls on, though, then you’ve put all your eggs into a small basket that’s easy to get wrong. Some of the best bass players I know have setups that will definitely go low – but that going low is in very careful and tasteful balance to other frequencies. The feel of the earth moving is a flavor enhancement to the basic and critical meal of all the notes being audible and properly proportioned to one another. If that fundamentally critical musical food wasn’t translated, I would no longer consider those players to be some of the best around.
There are other bass players that I know who I also consider to be top-shelf.
And their rigs don’t go very low.
But they are smooth and balanced, and fit perfectly into the equation of the band. That’s what really matters, and what really impresses me. Fourty Hz is rad for a minute, but there’s a universe of sound way above that neighborhood that’s necessary for being mind-blowing through a whole set.