The nature of experimentation is that your trial may not get you the expected results. Just ask the rocket scientists of the mid-twentieth century. Quite a few of their flying machines didn’t fly. Some of them had parts that flew – but only because some other part exploded.
This last week, I attempted to implement a remote-control system for the mixing console at my regular gig. I didn’t get the results I wanted, but I learned a fair bit. In a sense, I think I can say that what I learned is more valuable than actually achieving success. It’s not that I wouldn’t have preferred to succeed, but the reality is that things were working just fine without any remote control being available. It would have been a nice bit of “gravy,” but it’s not like an ability to stride up to the stage and tune monitors from the deck is “mission critical.”
The Background
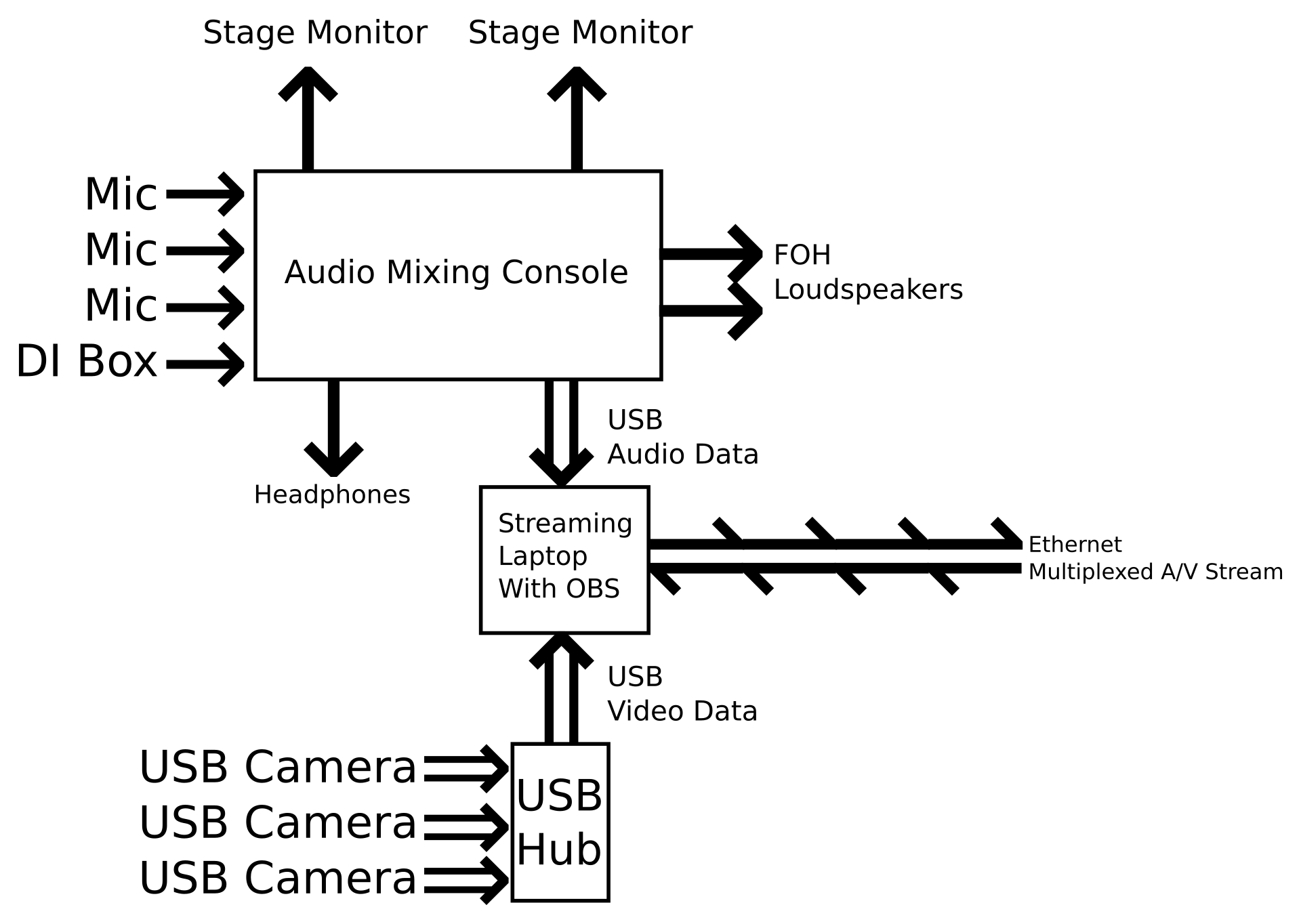
If you’re new to this site, you may not know about the mix rig that I use regularly. It’s a custom-built console that runs on general computing hardware. It started as a SAC build, but I switched to Reaper and have stayed there ever since.
To the extent that you’re talking about raw connectivity, a computer-hosted mix system is pre-primed for remote control. Any modern computer and accessible operating system will include facilities for “talking” to other devices over a network. Those connectivity facilities will be, at a basic level, easy to configure.
(It’s kind of an important thing these days, what with the Internet and all.)
So, when a local retailer was blowing out 10″ Android tablets for half price, I thought, “Why not?” I had already done some research and discovered that VNC apps could be had on Android devices, and I’ve set up VNC servers on computers before. (It’s not hard, especially now that the installers handle the network security configuration for you.) In my mind, I wasn’t trying to do anything exotic.
And I was right. Once I had a wireless network in place and all the necessary software installed, getting a remote connection to my console machine was as smooth as butter. Right there, on my tablet, was a view of my mixing console. I could navigate around the screen and click on things. It all looked very promising.
There’s a big difference between basic interaction and really being able to work, though. When it all came down to it, I couldn’t easily do the substantive tasks that would make having a remote a handy thing. It didn’t take me long to realize that tuning monitors while standing on the deck was not something I’d be able to do in a professional way.
A Gooey GUI Problem
At the practical level, the problem I was having was an interface mismatch. That is, while my tablet could display the console interface, the tablet’s input methodology wasn’t compatible with the interface being displayed.
Now, what the heck does that mean?
Reaper (and lots of other audio-workstation interfaces) are built for high-precision pointing devices. You might not think of a mouse or trackball as “high precision,” but when you couple one of those input devices with the onscreen pointer, high precision is what you get. The business-end of the pointer is clearly visible, only a few pixels wide, and the “interactivity radius” of the pointer is only slightly larger. There is an immediately obvious and fine-grained discrimination between what the pointer is set to interact with, and what it isn’t. With this being the case, the software interface can use lots of small controls that are tightly packed.
Additionally, high-precision pointing allows for fast navigation across lots of screen area. If you have the pointer in one area of the screen and invoke, say, an EQ window that pops open in another area, it’s not hard to get over to that EQ window. You flick the mouse, your eye finds the pointer, you correct on the fly, and you very quickly have control localized to the new window. (There’s also the whole bonus of being able to see the entire screen at once.) With high-precision input being available, the workstation software can make heavy use of many independent windows.
Lastly, mice and other high-precision pointers have buttons that are decoupled from the “pointing” action. Barring some sort of failure, these buttons are very unambiguous. When the button is pressed, it’s very definitely pressed. Clicks and button holds are sharply delineated and easily parsed by both the machine and the user. The computer gets an electrical signal, and the user gets tactile feedback in their fingers that correlates with an audible “click” from the button. This unambiguous button input means that the software can leverage all kinds of fine-grained interactions between the pointer position and the button states. One of the most important of those interactions is the dragging of controls like faders and knobs.
So far so good?
The problem starts when an interface expecting high-precision pointing is displayed on a device that only supports low-precision pointing. Devices like phones and tablets that are operated by touch are low-precision.
Have you noticed that user interfaces for touch-oriented devices are filled with big buttons, “modal” elements that take over the screen, and expectations for “big” gestures? It’s because touch control is coarse. Compared to the razor-sharp focus of a mouse-driven pointer, a finger is incredibly clumsy. Your hand and finger block a huge portion of the screen, and your finger pad contacts a MASSIVE area of the control surface. Sure, the tablet might translate that contact into a single-pixel position, but that’s not immediately apparent (or practically useful) to the operator. The software can’t present you with a bunch of small subwindows, as the miniscule interface elements can’t be managed easily by the user. In addition, the only way for the touch-enabled device to know the cursor’s location is for you to touch the screen…but touch, by necessity, has to double as a “click.” Interactions that deal with both clicks and movement have to be forgiving and loosely parsed as a result.
Tablets don’t show big, widely spaced controls in a single window because it looks cool. They do it because it’s practical. When a tablet displays a remote interface that’s made for a high-precision input methodology, life gets rather difficult:
“Oh, you want to display a 1600 x 900, 21″ screen interface on a 1024 X 600, 10″ screen? That’s cool, I’ll just scale it down for you. What do you mean you can’t interact with it meaningfully now?”
“Oh, you want to open the EQ plugin window on channel two? Here you go. You can’t see it? Just swipe over to it. What do you mean you don’t know where it is?”
“Oh, you want to increase the send level to mix three from channel four? Nice! Just click and drag on that little knob. That’s not what you touched. That’s also not what you touched. Try zooming in. I’m zoomi- wait, you just clicked the mute on channel five. Okay, the knob’s big now. Click and drag. Wait…was that a single click, or a click and hold? I think that was…no. Okay, now you’re dragging. Now you’ve stopped. What do you mean, you didn’t intend to stop? You lifted your finger up a little. Try again.”
With an interface mismatch, everything IS doable…but it’s also VERY slow, and excruciatingly difficult compared to just walking back to the main console and handling it with the mouse. Muting or unmuting a channel is easy enough, but mixing monitors (and fighting feedback) requires swift, smooth control over lots of precision elements. If the interface doesn’t allow for that, you’re out of luck.
Control States VS. Pictures Of Controls
So, can systems be successfully operated by remotes that don’t use the same input methodology as the native interface?
Of course! That’s why traditional-surface digital consoles can be run from tablets now. The tablet interfaces are purpose-built, and involve “state” information about the main console’s controls. My remote-control solution didn’t include any of that. The barrier for me is that I was trying to use a general-purpose solution: VNC.
With VNC, the data transmitted over the network is not the state of the console’s controls. The data is a picture of the console’s controls only, with no control-state data involved.
That might seem confusing. You might be saying, “But there is data about the state of the controls! You can see where the faders are, and whether the mutes are pressed, and so on.”
Here’s the thing, though. You’re able to determine the state of the controls because you can interpret the picture. That determination you’ve made, however, is a reconstruction. You, as a human, might be seeing a picture of a fader at a certain level. Because that picture has a meaning that you can extract via pattern recognition, you can conceptualize that the fader is in a certain state – the state of being at some arbitrary level of gain. To the computer, though, that picture has no meaning in terms of where that fader is.
When my tablet connects to the console via VNC, and I make the motions to change a control’s state, my tablet is NOT sending information to the console about the control I’m changing. The tablet is merely saying “click at this screen position.” For example, if clicking at that screen position causes a channel’s mute to toggle, that’s great – but the only machine aware of that mute, or whether that mute is engaged or disengaged, is the console itself. The tablet itself is unaware. It’s up to me to look at the updated picture and decide what it all means…and that’s assuming that I even get an updated picture.
The cure to all of this is to build a touch-friendly interface which is aware of the state of the controls being operated. You can present the knobs, faders, and switches in whatever way you want, because the remote-control information only concerns where that control should be set. The knobs and faders sit in the right place, because the local device knows where they are supposed to be in relation to their control state. Besides solving the “interface mismatch” problem, this can also be LIGHT YEARS more efficient.
(Disclaimer: I am not intimately aware of the inner workings of VNC or any console-remote protocol. What follows are only conjectures, but they seem to be reasonable to me.)
Sending a stream of HD (or near HD) screenshots across a network means quite a lot of data. If you’re using jpeg-esque compression, you can crush each image down to 100 kilobytes and still have things be usable. VNC can be pretty choosy about what it updates, so let’s say you only need one full image every second. You won’t see meters move smoothly or anything like that, but that’s the price for keeping things manageable. The data rate is about 819 kbits/ second, plus the networking overhead (packet headers and other communication).
Now then. Let’s say we’ve got some remote-control software that handles all “look and feel” on the local device (say, a tablet). If you represent a channel as an 8-bit identifier, that means you can have up to 256 channels represented. You don’t need to actually update each channel all the time to simply get control. Data can just be sent as needed, of course. However, if you want to update the channel meters 30 times per second, that meter data (which could be another 8-bit value) has to be attached to each channel ID. So, 30 times a second, 256 8-bit identifiers get 8-bits of meter information data attached to each of them. Sixteen bits multiplied by 256 channels, multiplied by 30 updates/ second works out to about 123 kbits/ second.
Someone should check my math and logic, but if I’m right, nicely fluid metering across a boatload of channels is possible at less than 1/6th the data rate of “send me a screenshot” remote control. You just have to let the remote device handle the graphics locally.
Control-state changes are even easier. A channel with fader, mute, solo, pan, polarity, a five-selection routing matrix, and 10 send controls needs to have 20 “control IDs” available. A measly little 5-bit number can handle that (and more). If the fader can handle 157 “integer” levels (+12 dB to -143 dB and “-infinity”) with 10 fractional levels of .1 dB between each integer (1570 values total), then the fader position can be more than adequately represented by an 11-bit number. If you touch a fader and the software sends a control update every 100th of a second, then a channel ID, control ID, and fader position have to be sent 100 times per second. That’s 24 bits multiplied by 100, or 2.4 kbits/ second.
That’s trivial compared to sending screenshots across the network, and still almost trivial when compared to the “not actually fast” data rate required to update the meters all the time.
Again, let me be clear. I don’t actually know if this is how “control state” remote operation works. I don’t know how focused the programmers are on network data efficiency, or even if this would be a practical implementation. It seems plausible to me, though.
I’m rambling at this point, so let me tie all this up: Remote control is nifty, and you can get the basic appearance of remote control with a general purpose solution like VNC. If you really need to get work done in a critical environment, though, you need a purpose built solution that “plays nice” at both the local and remote ends.
 Want to use this image for something else? Great! Click it for the link to a high-res or resolution-independent version.
Want to use this image for something else? Great! Click it for the link to a high-res or resolution-independent version.